The next crowd worker? Can ChatGPT estimate approval levels in speeches in the EU Council of Ministers?
Authors: Zuzanna Krakowska, Robin Rauner, and Gayathri Shankar
Date: 10 May 2024
The advent of accessible artificial intelligence like ChatGPT has transformative implications for society. To explore the utility of Large Language Models (LLMs) in academic research, we compare the performance of OpenAI’s most recent Generative Pre-Trained Transformers (GPTs) to human estimations of general approval in speeches made during deliberations in the Council of the European Union. We find that LLMs have the potential to accelerate the analysis of large datasets and alleviate an enduring issue in the social sciences: the high cost, relative scarcity, and time limitations of expert text annotators.
The field of social sciences has long struggled with the issues of high cost, scarcity, and time limitations when employing experts to conduct analyses of source material. With the proliferation of data in the form of political texts, the limitations of human resources have become more apparent. While automated text analysis methods allow researchers to explore extensions of human-annotated text data, replicating human experts with limited input from researchers has not yet been possible. Recent technological advancements provide a promising new avenue for reproducing the human gold standard at scale. Trained on colossal amounts of text to predictively generate natural language, Large Language Models (LLMs) may provide an alternative to human labour, particularly for conducting text analyses. However, more systematic research is needed to develop best practices for using LLMs in political science studies.
The experiment
To test whether LLMs are a viable alternative to existing automated text processing methods or even to human experts, we applied three of OpenAI’s most recent LLMs to transcribed videos of negotiations between government ministers in the Council of the European Union. GPT-3.5 Turbo, GPT-4, and the most recent GPT-4 Turbo were applied to Member States’ interventions during the Economic and Financial Affairs Council (ECOFIN) configuration proceedings. We instructed the LLMs to measure Member State’s expressed agreement with the policy proposal under negotiation on a five-point Likert scale ranging from ‘strongly agree’ (one) to ‘strongly disagree’ (five). The transcription text and human coders’ estimates of general approval were derived from the Deliberations in the Council of the European Union (DICEU) dataset (Wratil and Hobolt, 2019).
Our results
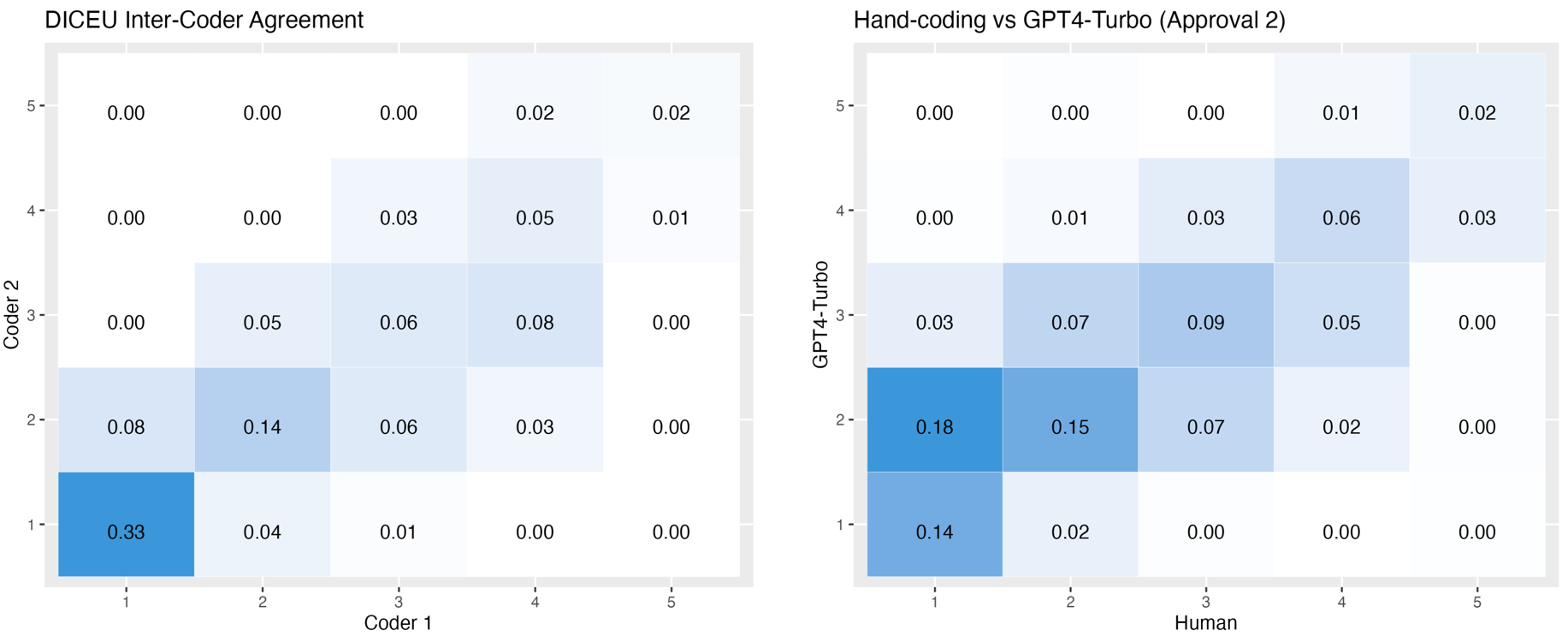
In Figure 1, we compare human and LLM estimations of general approval. The heat map on the left illustrates the degree of agreement between the two human annotators employed by the creators of the DICEU dataset. The heat map on the right compares the output generated by GPT-4 Turbo to human judgement of the degree of approval expressed in Council speeches. Darker shades of blue aligning diagonally, rising from the heat map's lower left to upper right corners, demonstrate higher agreement. The numbers indicated in each square refer to the proportion of human/GPT coders' judgements that overlap on a particular point on each human/GPT coders' Likert scale. For example, the blue boxes at the bottom left corners of the heat maps display the percentage of speeches that both coders assigned the value of one (full approval).
Compared to human coders, the LLMs displayed a bias towards moderate approval, outputting two far more often than any other value. We saw this trend lessen for the newest model, GPT-4 Turbo, which outputs a much higher proportion of three’s (balanced approval) than the earliest model, GPT-3.5 Turbo. The superior ability of GPT-4 Turbo to identify balanced approval is a clear advantage of using the most recent model. Still, GPT-4 Turbo struggles to distinguish between full and moderate approval in a way that replicates human judgement. An ideal heat map for GPT-4 would more closely mirror the inter-coder agreement distribution seen in the DICEU coders' heat map.
Prompt engineering to improve GPT performance
One open question that arises when asking both humans and LLMs to complete a coding task is how to optimise the description of the task at hand. A unique advantage of using LLMs is the ability to “program” them using natural language, similar to training human coders. Comparing the performance of LLMs to human coders allowed us to experiment with definition wording and iteratively fine-tune the use of natural language to define general approval. We increased the complexity of general approval definitions three times and repeated the classification process. We found that the older GPT models perform better with simple tasks. The newest model, however, performed better with more complex concept definitions, suggesting it may be the best suited for use in a social science setting, where such definitions tend to apply.
Figure 1: Proportional Heat Maps Comparing Human Experts and GPT-4 Turbo Output
Conclusions
Our results show that the latest OpenAI model, GPT-4 Turbo, performs particularly well at identifying balanced expressions of approval. In fact, the proportion of speeches assigned the value three by the GPT and hand-coding is higher than between the two DICEU coders, as seen in Figure 1. Another takeaway from our comparison of GPT models is the decreasing accuracy of GPT-3.5 Turbo as prompt complexity increases. The opposite is true for GPT-4 Turbo, with inter-coder reliability jumping nearly five percentage points after adding more detail to the definition of general approval.
Future research could employ further fine-tuning using the few-shot approach, potentially leading to substantial improvements for GPT-4 and GPT-4 Turbo. Including an optimised selection of correct examples may successfully adapt the GPT models to decipher the nuanced diplomatic language that characterises the Council’s negotiations. Another solution must be found for the lack of key context, such as when a speaker refers to a policy position previously stated by other ministers, which is unknown to the GPT. Despite the GPT models in our trial not matching the human coders precisely, we find that the newer LLMs can be adjusted significantly and possibly replicate human coders in the future. In particular, we recommend applying a few-shot analysis to GPT-4 Turbo, considering the notable increase in reliability for our pilot of the few-shot prompt. Further research into applying LLMs in the social sciences will undoubtedly help overcome the financial and resource constraints of manual text analysis.