# This is a chunk of R code. All text after a # symbol is a comment
# Set working directory using setwd() function
setwd('Enter the path to my working directory')
# Clear all variables in R's memory
rm(list=ls()) # Standard code to clear R's memoryImporting Data into R
A tutorial about data analysis using R (Website Version)
How to Read this Tutorial
This tutorial is a mixture of R code chunks and explanations of the code. The R code chunks will appear in boxes.
Below is an example of a chunk of R code:
Sometimes the output from running this R code will be displayed after the chunk of code.
Here is a chunk of code followed by the R output
2 + 4 # Use R to add two numbers[1] 6Objectives
The objectives of this tutorial are:
- Demonstrate good practise in data organisation
- Introduce plain text file formats for data
- Explain data import into R
Organise yourself!
Before you start importing data into R you should take time to organised your workspace on your computer:

- Create a folder on your computer to contain all your work for this particular project (e.g. a folder calledDataModule)
- Inside this project folder create another folder called
data. This will hold all the raw data files. These raw data files should not be changed. - Inside this project folder create a text file called
MyFirstScript.R. You can useRStudiofor this (for this useFile->New File->R Scriptmenu option) or any basic text editor to do this (e.g. Notepad, TextEdit, gedit, emacs). This file will be your R script that will contain all the commands for R. The.ror.Rsuffixes is the standard suffix for an R script. - If you are starting a large project consider creating separate folder for:R scripts,figures,output from the R script
Your first R script
Now you have created the fileMyFirstScript.Ryou should put some header text at the start of the file to explain what the R script will do. This was described in tutorial 1.
 Video Tutorial:Creating a new R script with RStudio (1 min)
Video Tutorial:Creating a new R script with RStudio (1 min)
The text should have a short explanation of the R script followed by your name and the date you wrote the R script. Each line should start with a#so that the text is not interpreted by R (this text is for humans so they understand what the file is intended to do). Here is an example,
# ********** Start of header **************
# Title: <The title of your R script>
#
# Add a short description of the R script here.
#
# Author: <your name> (email address)
# Date: <today's date>
#
# *********** End of header ****************
# Two common commands at the start of an R script are:
rm(list=ls()) # Clear R's memory
setwd('~/DataModule') # Set the working directory
# Replace '~/DataModule' with the name of your own directory
# ******************************************
# Write your commands below.
# Remember to use comments to explain your commands
Writing clear R scripts
An R script isn’t just telling the computer how to perform calculations on your data. It is also explaining your working to other human beings.
“Instead of imagining that our main task is to instruct a computer what to do, let us concentrate rather on explaining to human beings what we want a computer to do.”– Donald E. Knuth
To make your R scripts usable by humans they must be clearlycommented(using the#symbol to start a comment) and clearly organised.
As you write an R script consider these questions:
- Does your R script look well organised (e.g. is it well spaced, are lines indented logically)?
- Could someone else read the R script and understand the basic idea?
- Could someone else modify your R script relatively easily?
- In a couple of months time could youquicklyread and edit your own R script?
Professional data analysts take clarity very seriously. Here are some links to R coding style guides:
- Google’s style guide,(opens in a new window)https://google.github.io/styleguide/Rguide.xml
- Hadley Wickham’s style guide,(opens in a new window)http://adv-r.had.co.nz/Style.html
- (opens in a new window)http://www.stat.ubc.ca/~jenny/STAT545A/block19_codeFormattingOrganization.html
- (opens in a new window)http://nicercode.github.io/blog/2013-04-05-why-nice-code/
Data Workflow
Below is a schematic of the workflow for handling data.
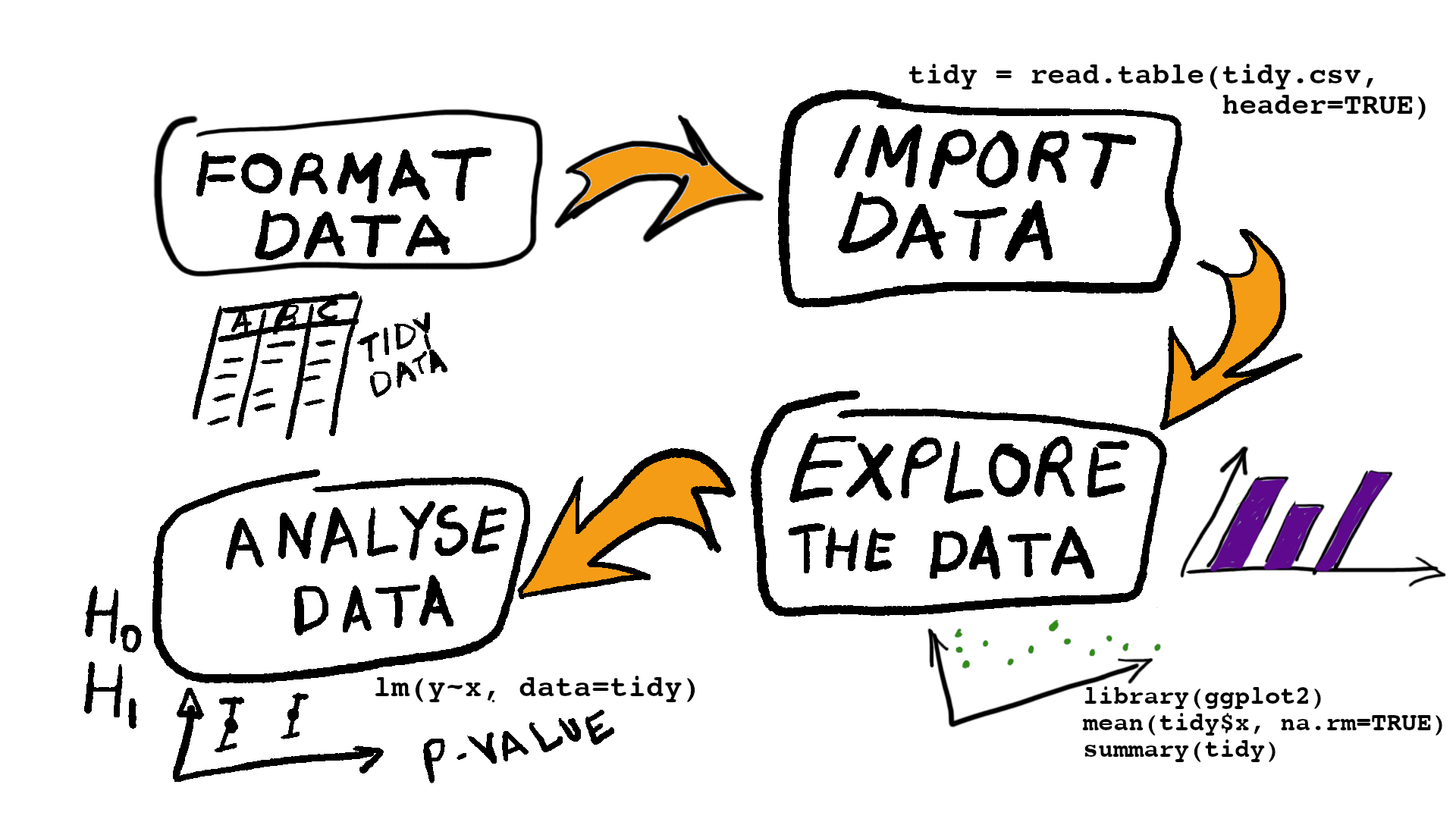
In this tutorial we will consider formating data, in the next tutorial we’ll discuss importing data, and then we’ll start to consider exploring the data using graphics and numerical summaries.
Format your data (tidy data)
The workflow starts long before you analyse your data. It starts even before you have your data in some computer software.
Organising your data should followtidy data guidelines(see below) and be plannedbefore you collect your data. The format of the data should be finalisedbefore importing the data into R. It is often easiest to tidy your data using a spreadsheet program before you import the data into R.
Well organised data from the start will make your life a lot easier and your data import as painless as possible.
Six guidelines for tidy data
When tidying your data you should ensure that:
- each variable has its own column
- each row is an observation
- the top of each column contains the name of the variable
- there are no blank columns or blank rows between data
- all data in a column has the same type (e.g. it is all numerical data, or it is all text data)
- data are consistent (e.g. if a binary variable can take values ‘Yes’ or ‘No’ then only these two values are allowed, with no alternatives such as ‘Y’ and ‘N’)
 PDF Summary:This PDF document reiterates the concept of tidy data
PDF Summary:This PDF document reiterates the concept of tidy data
The link to the PDF is:http://www.ucd.ie/ecomodel/pdf/TidyData.pdf
Poorly vs well formatted data
The data set shown in the figure below are an example of poorly formatted data. The data set contains data on the lead concentrations (ppm) from three species of fish (whitefish, sucker and trout). Two types of sample were collected: samples from fillets of fish and from whole fish. The data has three variables: lead concentration, species of fish and type of fish sample.
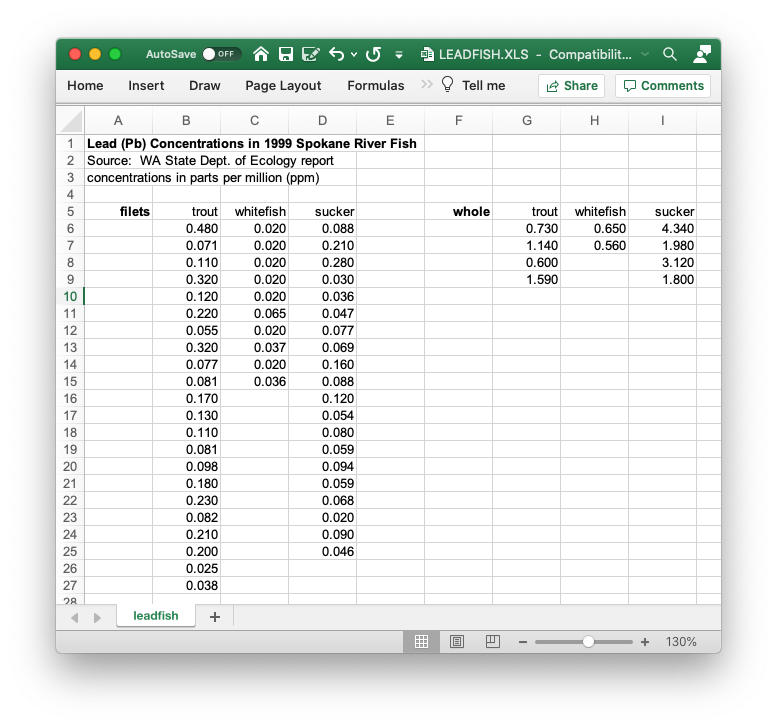
Figure: A poorly formatted data set. This file would be hard to import and analyse in this format.
How would you improve the format of the poorly formatted data shown in the figure? (Hint: use the six guidelines above)
The second figure shows some well formatted data that follows the tidy data guidelines: each column represents a single variable and each row an observation.
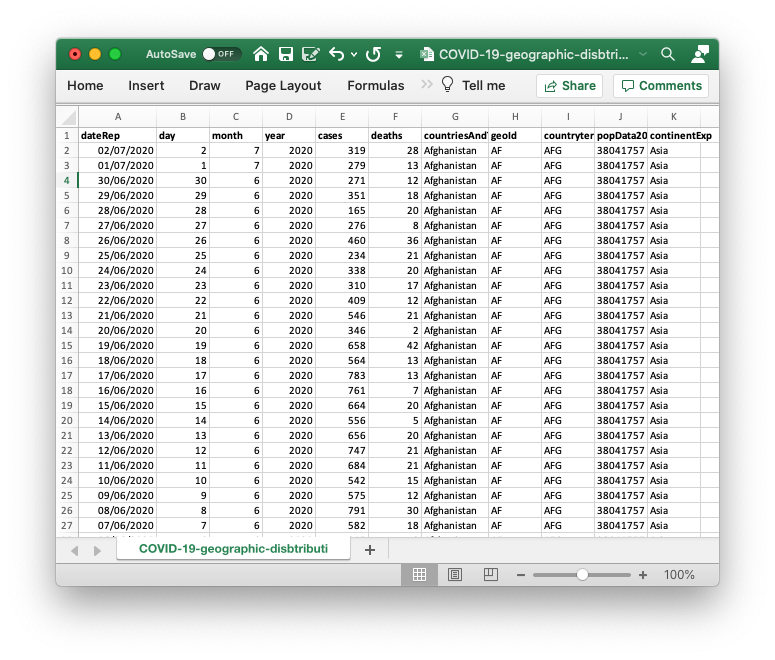
Figure: A well formatted data set. This file would be easy to import and analyse in this format. One column contains the data for one variable. These data are the worldwide occurences of Covid-19, downlaoded from the European Centre for Disease Prevention and Control,(opens in a new window)https://www.ecdc.europa.eu/en
Data frames
Adata frameis R’s name for spreadsheet data (e.g. data organised in a grid, like Excel). R stores the vast majority of data as a data frame and uses data frames when analyzing data.
A data frame forces the data to be well organised.
- Each column is a variable. The name of this variable becomes the name of the column.
- Each row corresponds to an observation. This meas that values in the same row are data collected about the same object. Rows can also have names.
Below is an example of a data frame (calledairquality) that contains data on the air quality in New York from May - September 1973 (this is a data set that is built in to R).
# The airquality data is a built-in dataset
# First 10 rows of the airquality data frame
head(airquality, n=10) Ozone Solar.R Wind Temp Month Day
1 41 190 7.4 67 5 1
2 36 118 8.0 72 5 2
3 12 149 12.6 74 5 3
4 18 313 11.5 62 5 4
5 NA NA 14.3 56 5 5
6 28 NA 14.9 66 5 6
7 23 299 8.6 65 5 7
8 19 99 13.8 59 5 8
9 8 19 20.1 61 5 9
10 NA 194 8.6 69 5 10You can type?airqualityto display the help file for this data set. The data frame has 154 rows (observations) and 6 columns (variables measured). The 6 columns contain data on: ozone concentrations (parts per billion), solar radiation, wind speed, air temperature, month and day of observation. You can see that each column has a name corresponding to the data for that column.
The structure of the data frame can be viewed using thestr()function
# Display the structure of the airquality data frame
str(airquality)'data.frame': 153 obs. of 6 variables:
$ Ozone : int 41 36 12 18 NA 28 23 19 8 NA ...
$ Solar.R: int 190 118 149 313 NA NA 299 99 19 194 ...
$ Wind : num 7.4 8 12.6 11.5 14.3 14.9 8.6 13.8 20.1 8.6 ...
$ Temp : int 67 72 74 62 56 66 65 59 61 69 ...
$ Month : int 5 5 5 5 5 5 5 5 5 5 ...
$ Day : int 1 2 3 4 5 6 7 8 9 10 ...Thestr()function shows that this is a data frame with 153 observations (rows) and six variables (columns). It also shows the data tyes of the variables: wind is a numerical variable (i.e. continuous) and the other variables are all integers (i.e. whole numbers).
Tidy datain R is described in more detail on this web page:(opens in a new window)https://cran.r-project.org/web/packages/tidyr/vignettes/tidy-data.html
Tibbles
A recent development (circa 2016) is an improved data frame called atibble. We will not discuss these new data frame objects here, but you can read about them at(opens in a new window)https://cran.r-project.org/web/packages/tibble/vignettes/tibble.html.
Don’t Panic! Tibbles are very similar to data frames.
The important point to know is that if you use RStudio’s GUI interface to import data then your data will be stored in atibble, not adata frame.
Importing spreadsheet data
To start working with data in R you need to import your data into R. You are aiming to have adata framethat contains your data.
The simplest way to import data into R is from a text file ((opens in a new window)https://en.wikipedia.org/wiki/Text_file). Text files (sometimes called flat files) can be read by any computer operating system and by many different statistical programs. Saving data as a simple text file makes your datahighly transportable.
Importing data from software specific formats (e.g. Excel’s .XLSX format, Minitab’s .MTW format, SPSS’s .SAV format or SAS’s .SAS format) is possible (e.g. using RStudio’sImport DatasetGUI). If you want your data to be easily shared with other people then use a text file to store your data.
We advise you to:
- save your data as a text file (software, such as Excel, often have an option to save data as plain text)
- organize data with columns corresponding to different variables before exporting to the text file
- use a visible text character to delimit each column (usually a comma, semi-colon). Using an invisible character (e.g. a space or a TAB) is not recommended because these characters all look the same at first glance.
General advice on importing data into R can be found at(opens in a new window)https://cran.r-project.org/doc/manuals/r-release/R-data.html
Converting data to a CSV text file
Acomma separated valuesfile (CSV file) is the most common format for a text file that contains data.
Here are a few video tutorials on converting data into a CSV text file so that it is suitable for import into R.
(opens in a new window)Video Tutorial:Converting data from EXCEL to a CSV format (3 mins)
(opens in a new window)Video Tutorial:Converting data from Googlesheets to a CSV format (1 min)
Viewing text files
Before importing a text file into any software package it is a huge help if you can look at it in a text editor. Text files can contain characters that are normally invisible (e.g. spaces, tabs and end of line markers). If a text editor is going to be of use it must be able todisplay all the charactersin a file.
Three text editors that can do this are:
(opens in a new window)notepad++is a free program for Windows operating systems
(opens in a new window)BBeditis a free program for Mac OSX operating systems
(opens in a new window)emacsis a GNU opensource program primarily for Linux operating systems.
On Linux systems thecat -Acommand from the terminal is also useful.
Here are two video tutorials on this topic
Video Tutorial:Viewing data in a text file before importing into R (4 mins)
Video Tutorial:An overview of the common data text file formats (3 mins)
Data import examples
The data we’ll be importing are described athttp://www.ucd.ie/ecomodel/Resources/datasets_WebVersion.html
The files are:
- WOLF.CSV: This file is a text file of comma separated values.
- HEIGHT.CSV: This file is a text file of comma separated values.
- INSECT.TXT:This file is a text file of TAB delimited values.
- BEEKEEPER.TXT: This file is a text file with blank space delimiting the values.
- MALIN_HEAD.TXT: This file is a text file with TAB delimited values.
All these data files are simpletext filesthat differ in the character used to distinguish columns of data.
Data import examples
The data we’ll be importing are described athttp://www.ucd.ie/ecomodel/Resources/datasets_WebVersion.html
The files are:
- WOLF.CSV: This file is a text file of comma separated values.
- HEIGHT.CSV: This file is a text file of comma separated values.
- INSECT.TXT:This file is a text file of TAB delimited values.
- BEEKEEPER.TXT: This file is a text file with blank space delimiting the values.
- MALIN_HEAD.TXT: This file is a text file with TAB delimited values.
All these data files are simpletext filesthat differ in the character used to distinguish columns of data.
Comma delimited files (CSV files)
CSV stands for comma separated values (notesometimes semi-colons are used in place of commas because some countries use the comma in place of the decimal point).
Theread.table()function is a flexible function for importing text data
Video Tutorial:Importing a CSV file into R using read.table() (5 mins)
# Import WOLF.CSV file using read.table function
wolf = read.table('WOLF.CSV', header=TRUE, sep=',')Thewolfvariable contains the imported data. It is called adata frame.
The ideal arrangement of a data frame is for each row to be an observation of some object and each columns a variable that measures some property of the object. For example, each row ofwolfis an observation of one individual wolf and each column ofwolfgive information about where the wolf was observed and the data collected from its hair sample.
The HEIGHT.CSV file also contains comma separated values. Here is theread.table()command to read in this file
# Import HEIGHT.CSV file using read.table function
human = read.table('HEIGHT.CSV', header=TRUE, sep=',')Note: The functionread.csv()is a special case of theread.table()function.
Use the R help pages to learn more about these functions
?read.table # Display help page on read.table functionTAB delimited files (TXT files)
The INSECT.TXT data set is a text file where variables are delimited by a TAB. In addition the first three lines contain a data description that we do not want to import.
Theread.table()function can be used to import this file. The argumentskip=3is used to ignore the first three lines. The argumentsep='\t'specifies a TAB as the variable delimiter
# Import INSECT.TXT file using read.table function (TAB delimited)
# skipping the first 3 lines (skip=3)
insect = read.table('INSECT.TXT', header=T, skip=3, sep='\t')The MALIN_HEAD.TXT also contains TAB delimited data. Here is theread.table()command to read in this file
# Import MALIN_HEAD.TXT file using read.table function (TAB delimited)
rainfall = read.table('MALIN_HEAD.TXT', header=T, sep='\t')Blank space delimited files
The BEEKEEPER.TXT data set uses white space to delimit the variables. The first six lines of the file contain a description of the data.
Usingread.table()with the argumentsep=''will interpret any space as a variable delimiter. Using the argumentskip=6will ignore the first 6 lines in the file and start importing data from the 7th line.
# Import BEEKEEPER.TXT file using read.table function (white space delimited)
# skipping the first 6 lines (skip=6)
bees = read.table('BEEKEEPER.TXT', header=T, skip=6, sep='')Summary of import commands
| Type of text file | R Command |
|---|---|
| Comma delimited (.CSV) | read.table(<filename>, header=T, sep=',') |
| TAB delimited (.TXT) | read.table(<filename>, header=T, sep='\t') |
| Blank space (.TXT) | read.table(<filename>, header=T, sep='') |
# Comma separated values
wolf = read.table('WOLF.CSV', header=TRUE, sep=',')
human = read.table('HEIGHT.CSV', header=TRUE, sep=',')
# TAB delimited values
insect = read.table('INSECT.TXT', header=T, skip=3, sep='\t')
rainfall = read.table('MALIN_HEAD.TXT', header=T, sep='\t')
# White space delimited values
bees = read.table('BEEKEEPER.TXT', header=T, skip=6, sep='')Importing data using RStudio
RStudio has its own data import functionality. To use this you will need to install the R packagereadr. For more inofmration about this see RStudio’s guide:(opens in a new window)https://support.rstudio.com/hc/en-us/articles/218611977-Importing-Data-with-RStudio
Video Tutorial:Importing a CSV file into R using RStudio’s GUI (3 mins 13 secs)
Importing data using RStudio will save the data as a modified data frame, called atibble(tibbles are briefly discussed above).
Importing usingfread()
fread()is a powerful data import function that is similar toread.table()but faster. It is part of thedata.tablepackage, which you will need to install.
You should only have to givefread()the name of the file you want to import, andfread()will try to work out the appropriate way to import the data. Try some examples and compare the the examples above
# ******************************************
# Other packages for importing data --------
# The data.table package
library(data.table) # Load the data.table package
# Import a CSV file
wolf2 = fread('WOLF.CSV')
human2 = fread('HEIGHT.CSV')
# Import TAB delimited file
insect2 = fread('INSECT.TXT')
rainfall2 = fread('MALIN_HEAD.TXT')
# Import white space delimited file
bees2 = fread('BEEKEEPER.TXT')Thefread()command is simpler to use because it tries to guess the format of the data in the file.
Summary of the topics covered
- Organizing your files on your computer
- Best practise for formatting data
- Reading in spreadsheet data
- Data frames
Further Reading
All these books can be found in UCD’s library
- Andrew P. Beckerman and Owen L. Petchey, 2012Getting Started with R: An introduction for biologists(Oxford University Press, Oxford) [Chapter 2, 3]
- Mark Gardner, 2012Statistics for Ecologists Using R and Excel(Pelagic, Exeter)
- Michael J. Crawley, 2015Statistics : an introduction using R(John Wiley & Sons, Chichester) [Chapter 2]
- Tenko Raykov and George A Marcoulides, 2013Basic statistics: an introduction with R(Rowman and Littlefield, Plymouth)